爬虫项目
爬虫笔记
爬取burst.shopify.com内容
[TOC]
总体思想
- 观察网页构造,为写代码做准备,检查是否有反爬技术
- 检查所要下载的图片,观察格式,并且构造正则表达式
- 过滤重复的图片
- 保存图片,并作相关优化
实现效果
- 可批量下载照片
- 可选择类别下载
- 编写面向对象程序爬取

前期准备
打开burst.shopify.com网页,观察其结构
观察到当我们打开一个类别的图片使,url中就将目录切换至类别下,这一点有助于我们后续的代码优化,可根据类别下载等
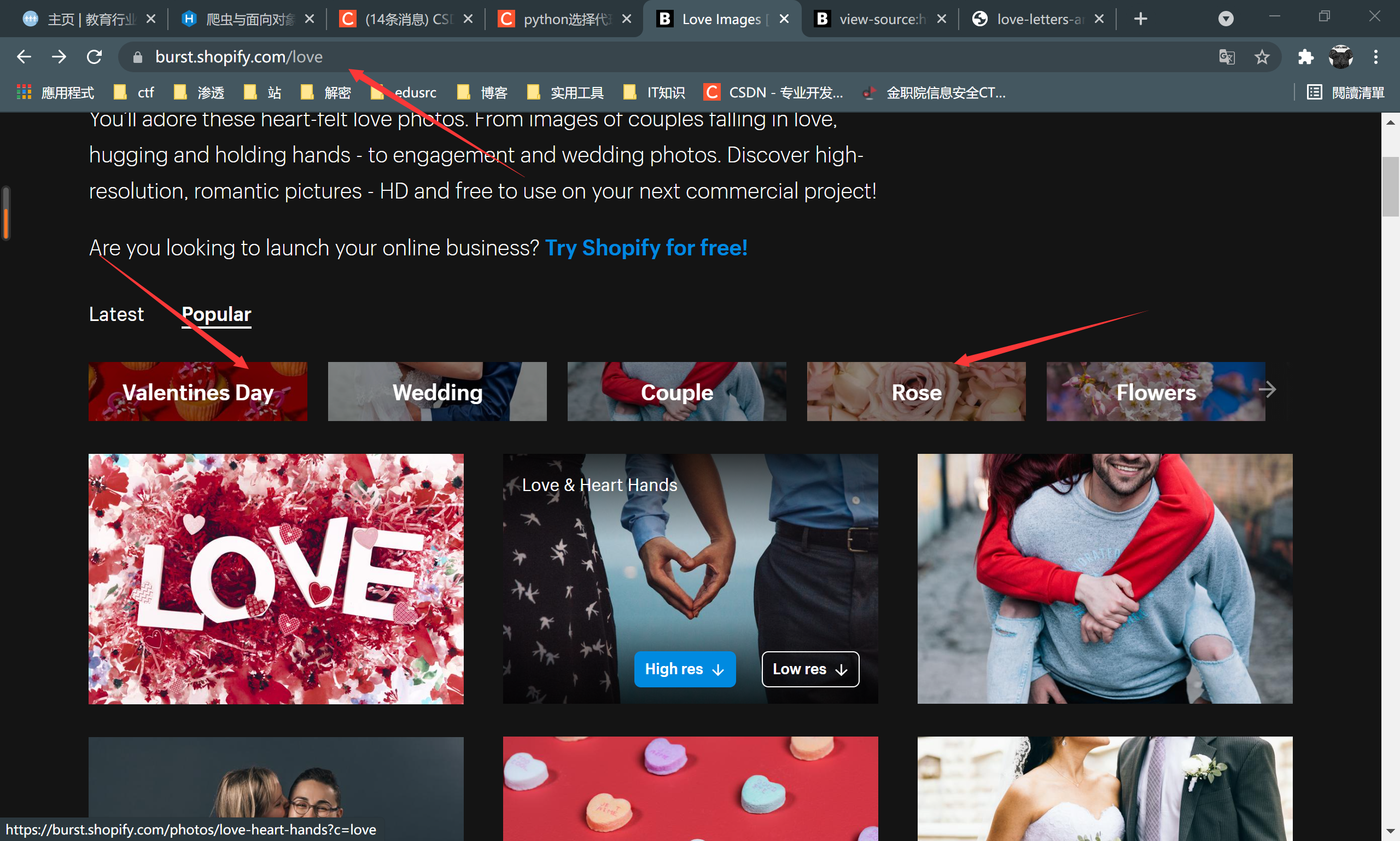
我们可以用F12观察网页源代码,根据图片的路径来进行爬虫的抓取

如上图,这一段就是这张图片在网页中的位置,我们打开图片的位置,在浏览器中显示图片
可以发现这里有一堆的jpg文件,并且都是一张照片,这里我就要想到后期要进行去重,不能有重复的照片显示出来
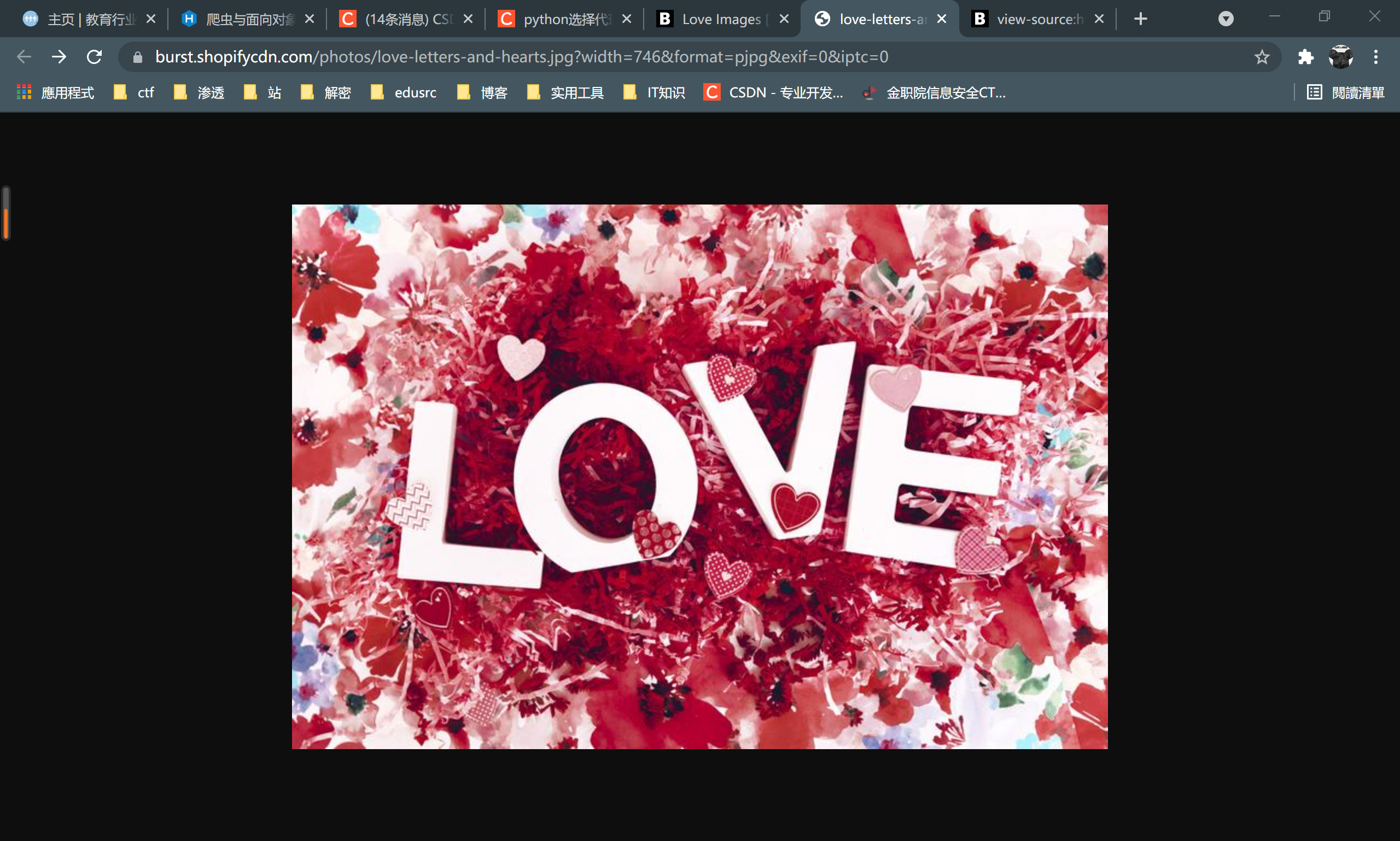
如上图,但是我们可以发现,这张图片并不是高清图片,观察url后可以发现,.jpg后面传参了一堆数据
https://burst.shopifycdn.com/photos/love-letters-and-hearts.jpg?width=746&format=pjpg&exif=0&iptc=0
我们将?后面的去掉后可以发现

变成了高清带图(这里试错了很多次)
这一部分有助于我们后面的正则过滤
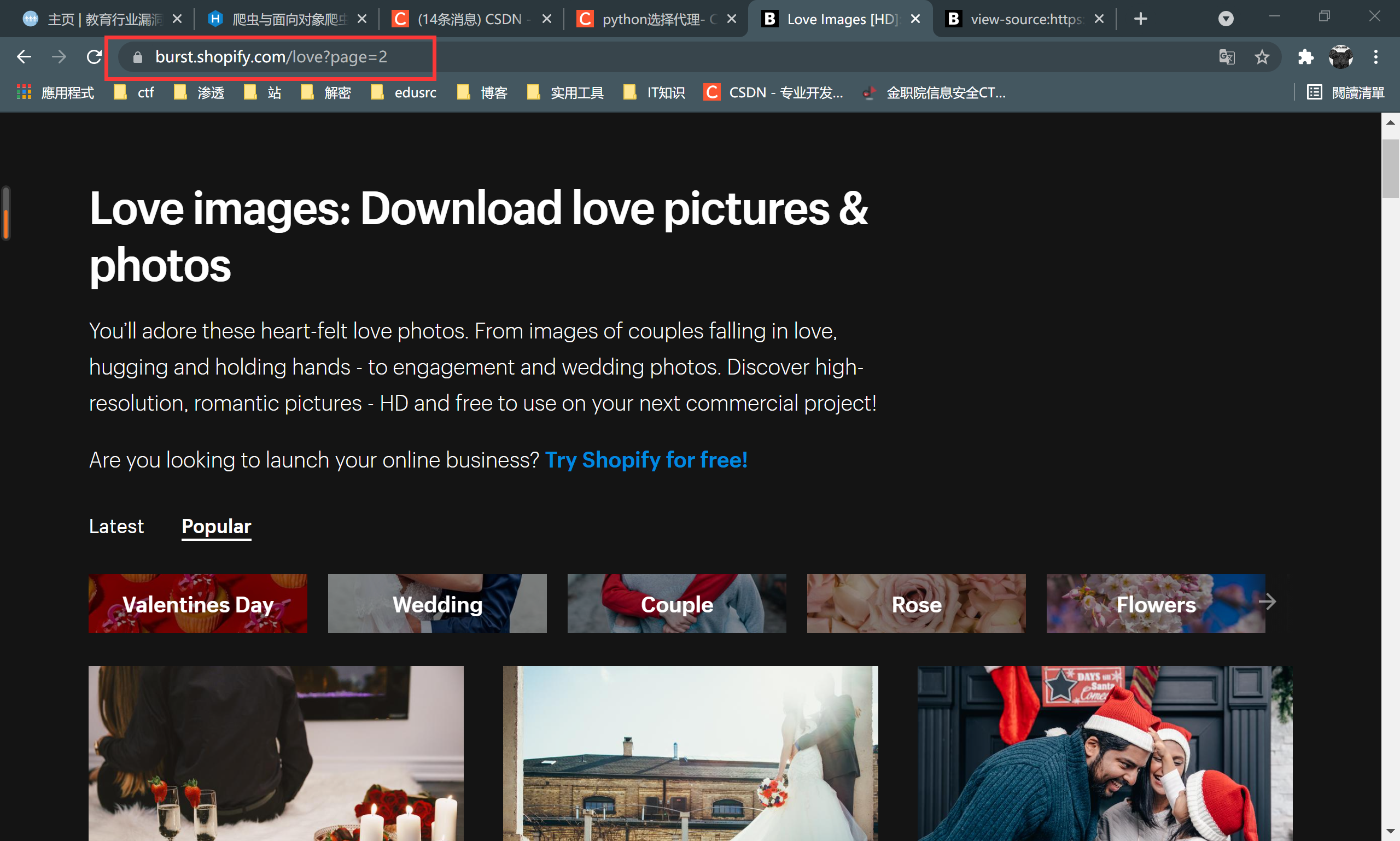
更换第二页时,url回显如上,有助于我们后期代码优化
代码编写

设置头,反爬

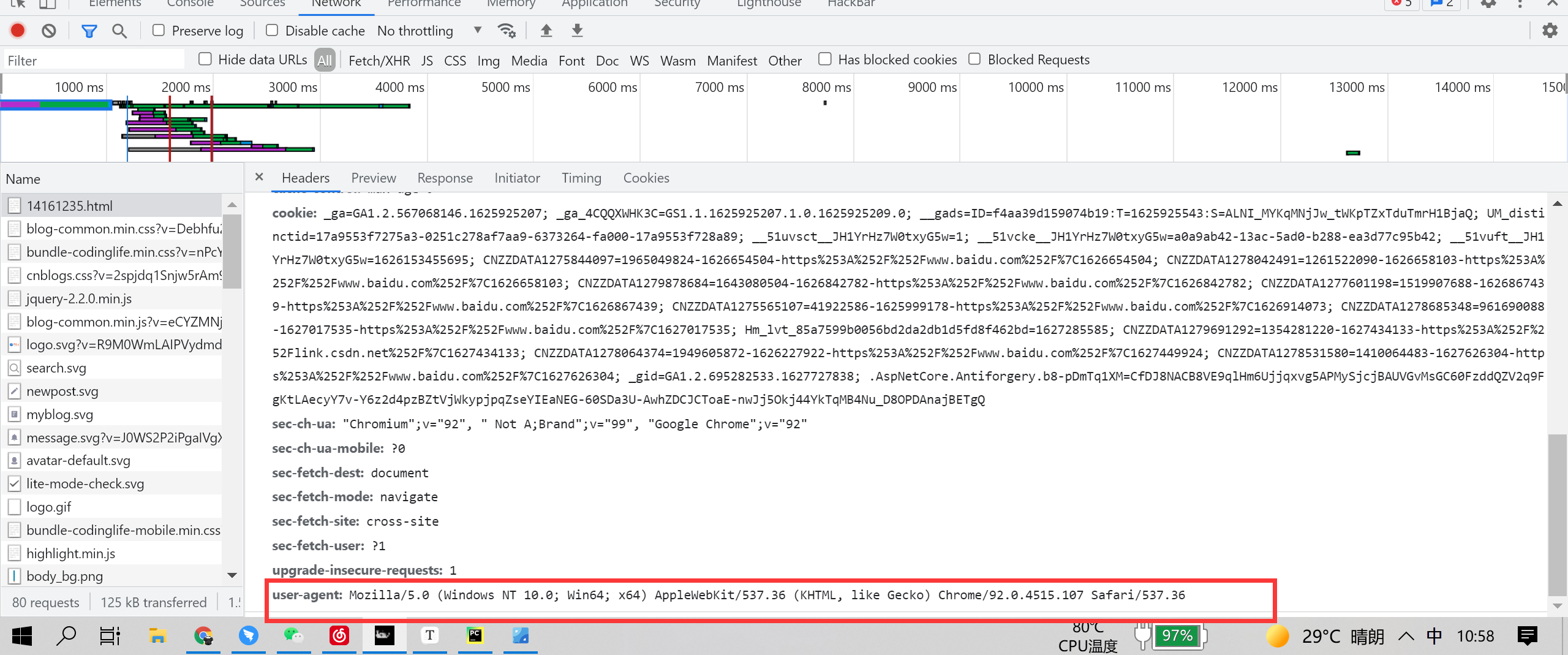
user-agent属性值为python-requests,在很多网站爬取的过程中,会被拦截
当被拦截时,请求失效
所以我们要伪装成一个正常的用户,这时设置头便是最简单的方法伪装成用户了
头的查看很简单,打开f12,下图中的红框框就是
我们在代码中提前申明,后面再调用即可
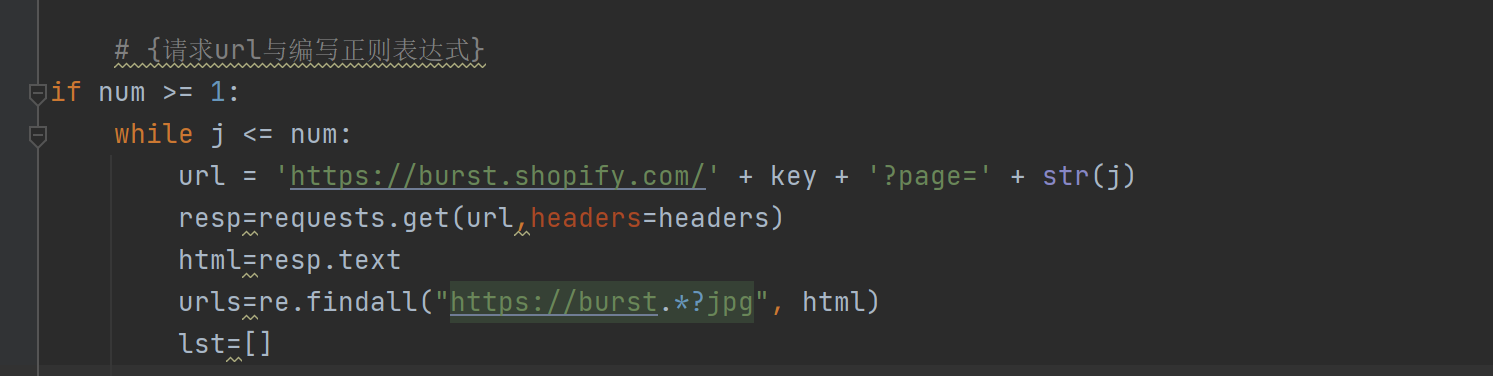

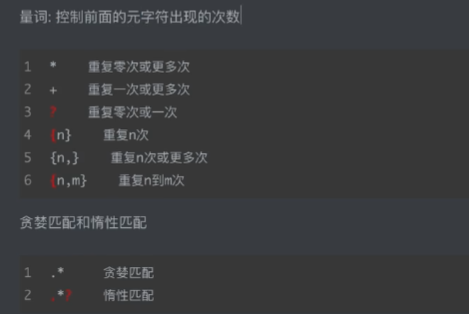
最常用的便是 .*? 可以过滤一些常用的,我这里也用到了
re.findall("https://burst.*?jpg", html)这段代码意思是使用re模块匹配源码 中为jpg的文件,并且只匹配到jpg,这也说明我们只匹配了高清大图,符合我们的需求

调试
- 根据图片位置为图片编号,以便后续操作
- 设置多页面下载
- 查看是否完全去重
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59'''
A.bin
21.7.22
'''
import re
import requests
x=0
j=1
count=0
print("'animals' 'city' 'home' 'seasons' 'education' 'landscape' 'family' \n "
"'love' 'around the world' 'arts' 'technology' 'outdoor' 'backgrounds' \n "
"'fashion' 'beauty' 'people' 'transportation' 'business' \n "
"'fitness' 'travel' 'flowers' 'work' 'food' 'holidays' 'celebrate'")
#{设置头,反爬}
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
}
key = input('请从上面挑选出要下载的图片类型:')
num = int(input('请输入一共要下载的页数:'))
# {请求url与编写正则表达式}
if num >= 1:
while j <= num:
url = 'https://burst.shopify.com/' + key + '?page=' + str(j)
resp=requests.get(url,headers=headers)
html=resp.text
urls=re.findall("https://burst.*?jpg", html)
lst=[]
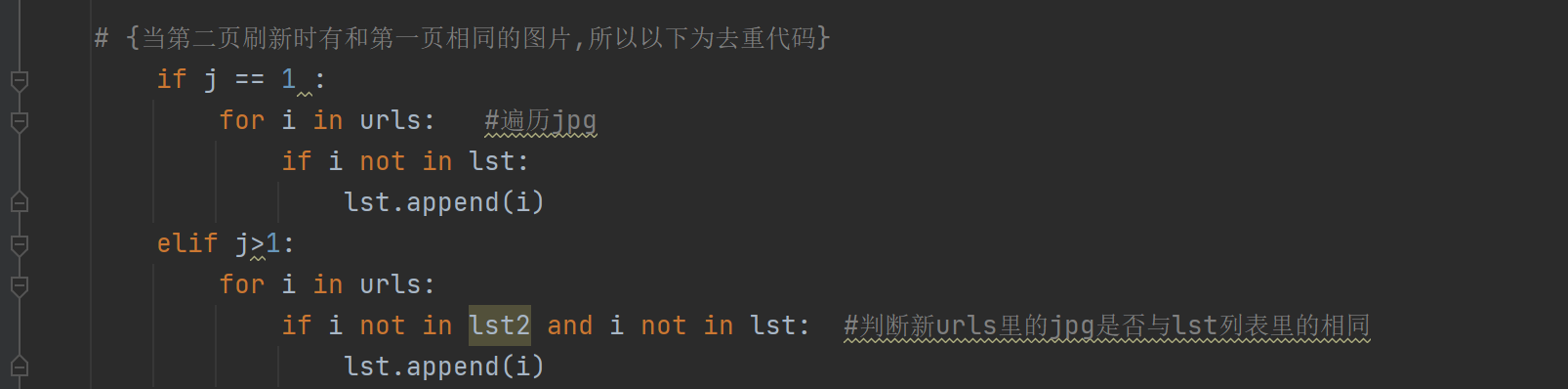
# {当第二页刷新时有和第一页相同的图片,所以以下为去重代码}
if j == 1 :
for i in urls: #遍历jpg
if i not in lst:
lst.append(i)
elif j>1:
for i in urls:
if i not in lst2 and i not in lst: #判断新urls里的jpg是否与lst列表里的相同
lst.append(i)
# {保存图片}
for url in lst:
file_name ="E:/大学/python爬虫/"+ str(j) + '.' + str(x) + ".jpg" #设置文件名
resp = requests.get(url, headers=headers)
with open(file_name, 'wb') as f: #以二进制的方式写进
f.write(resp.content)
print("正在下载第{0}页第{1}张图片".format(j,x))
x=x+1
# {计数部分}
if x==len(lst):
if j != 1:
pass # 这一部分if指lst2=lst只执行一次,
else:
lst2 = lst
x=0
j=j+1
count += len(lst)
print("下载完成!共下载{0}张图片".format(count))
最终效果
运行程序
根据分类可以进行选择下载的类型 选择 food 吧
选择页数后,即可下载
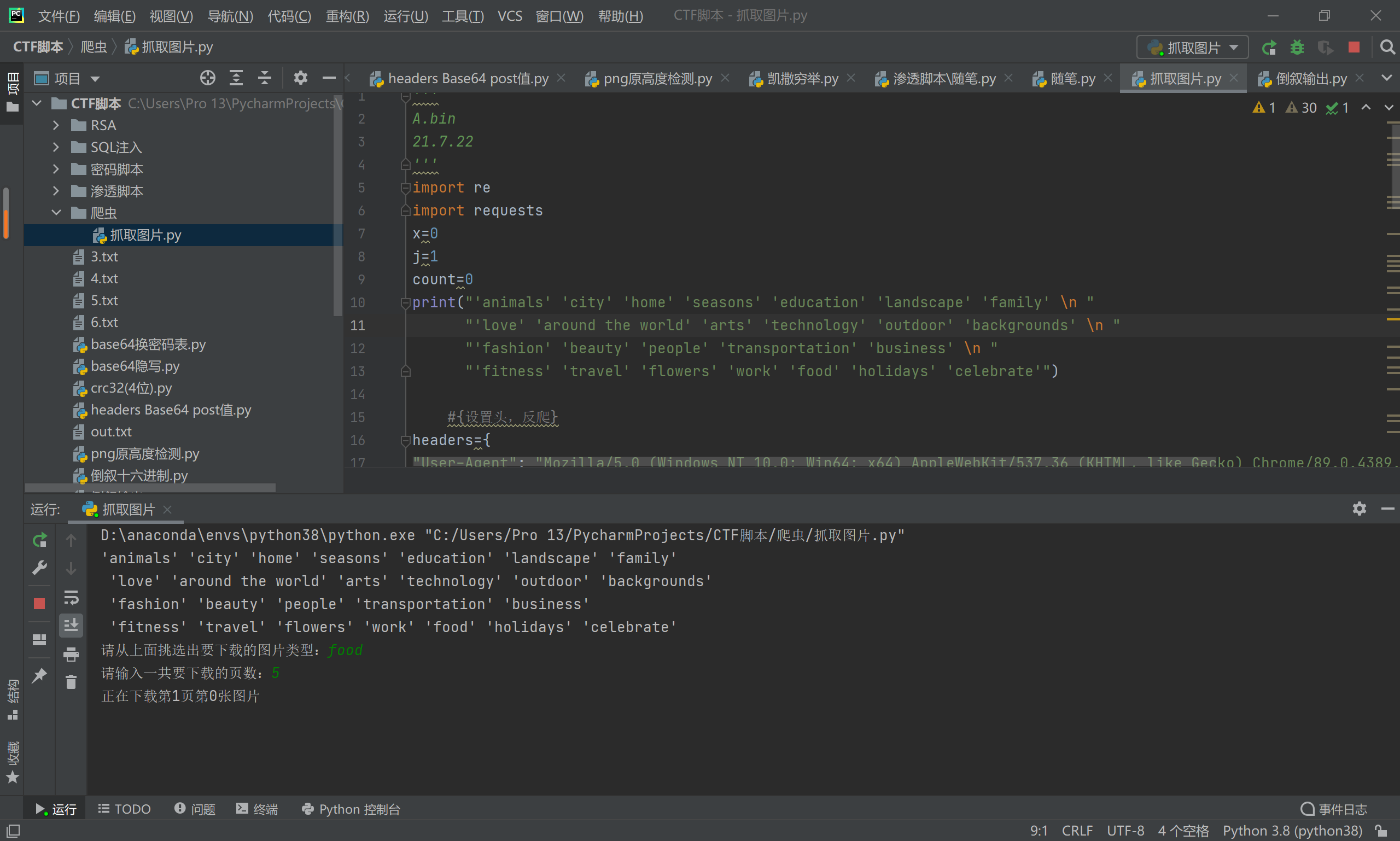
打开保存图片的文件夹,下载中……….

如下图,下载完成,显示最终下载数目
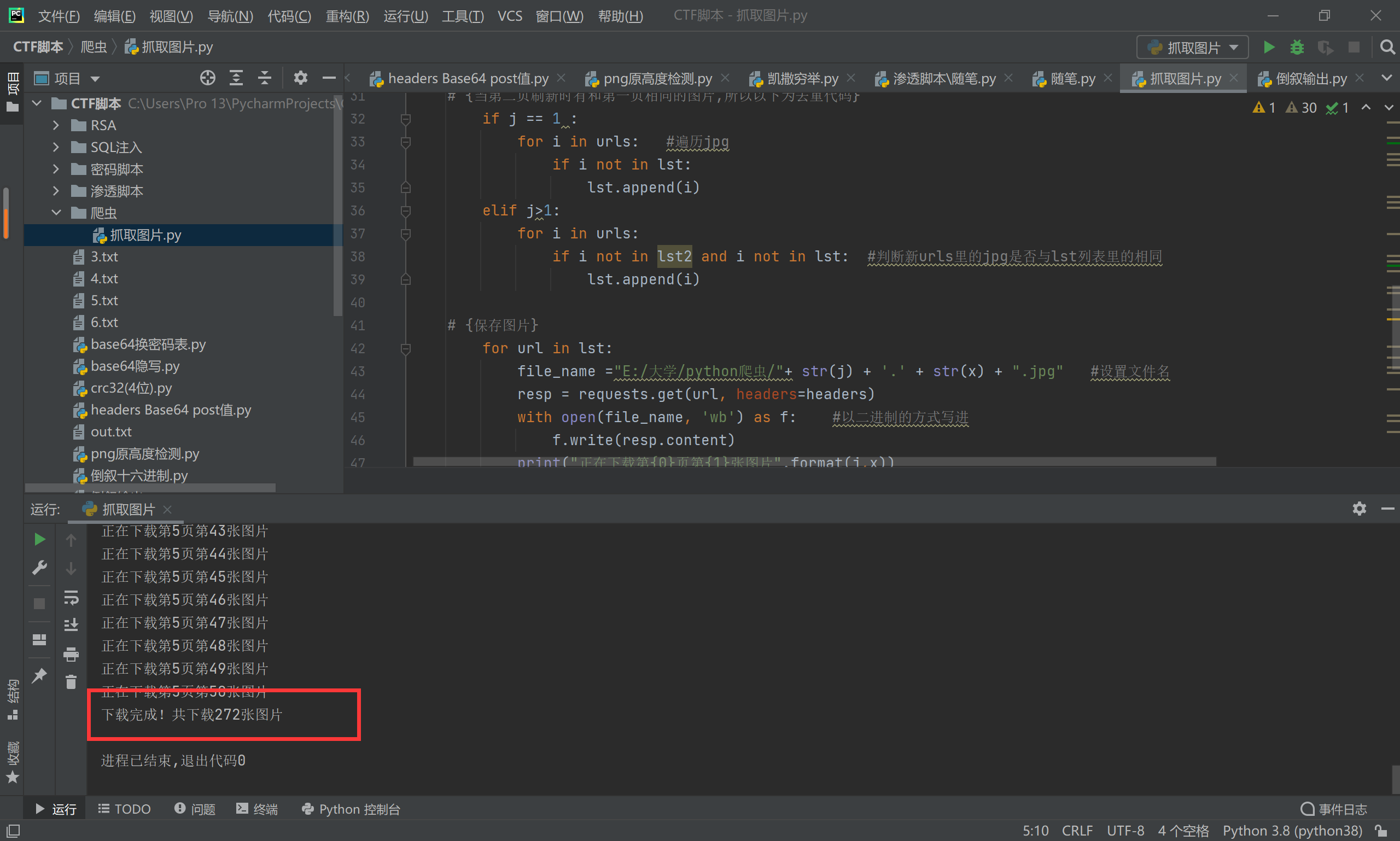
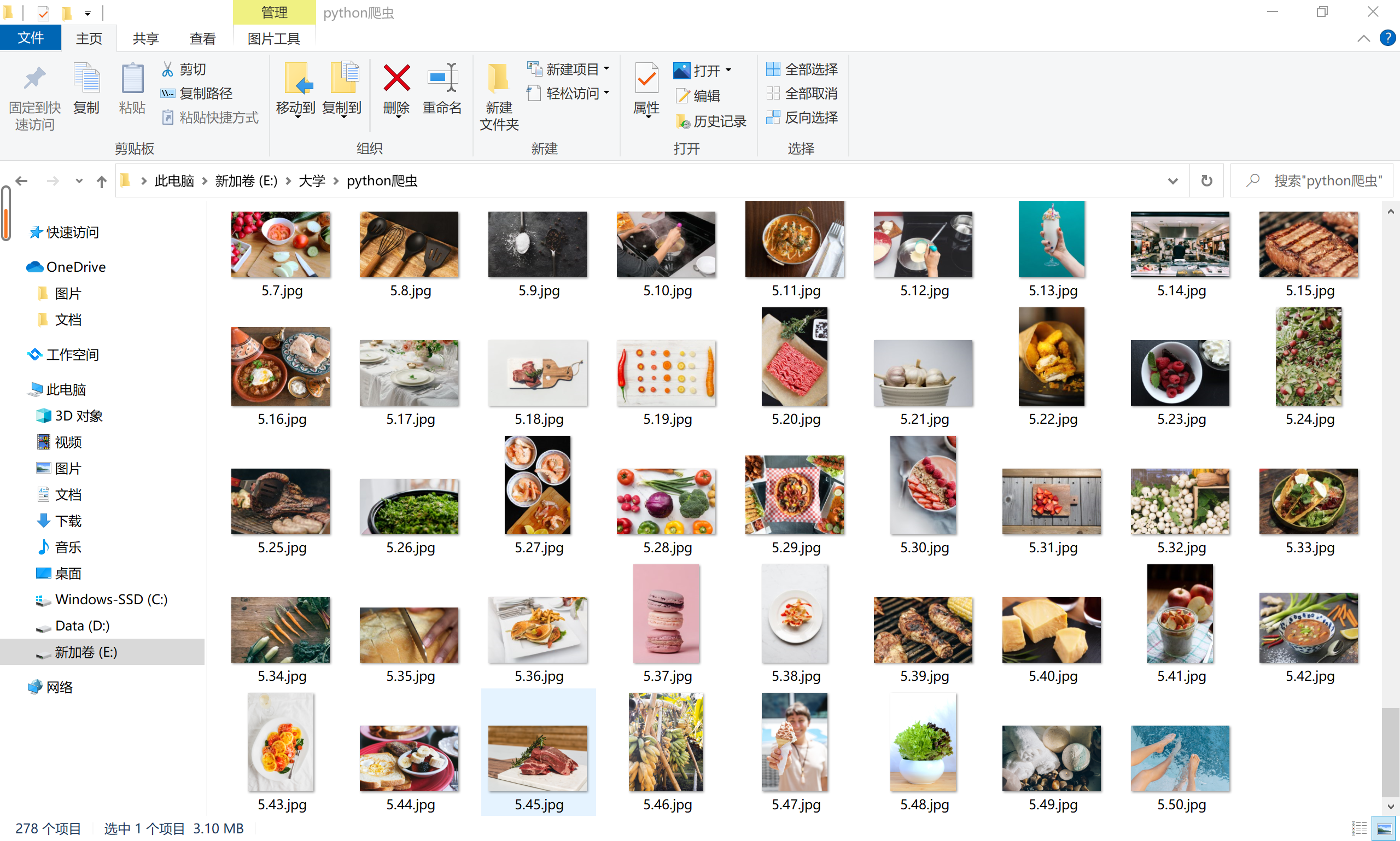
如下图,文件夹中塞满了图片,下载完成!
使用面向对象来爬取
面向对象也就是通过创建一个类,再创建若干个对象,然后再统一调动,我是在自己之前写的代码基础上进行修改
代码如下:
1 | import requests |
使用效果差不多,但缺少选择分类